分离重叠人声剪辑攻略,博主自用6款软件助你轻松处理人物声音重叠问题
相关内容:
多个人声重叠在一起,背景音嘈杂,怎么把想要的那个人声干净地剥离出来?尤其是采访视频或直播切片,多位嘉宾同时说话的情况非常普遍。传统的均衡器调节往往治标不治本,现在的 AI 智能分离技术才是国家队级别的表现。分享压箱底的 6 个人声分离工具。

方法一:转换猫 MP3 转换器 Windows(网页版)
转换猫 MP3 转换器 网页版是我个人在处理大批量素材时的首选。不仅支持格式转换,内置的人声分离功能是基于深度学习模型开发的,精准识别音频中的频谱特征。
1、启动软件后,在侧边栏找到“双人对话分离”功能模块。点击“添加文件”或直接将含有重叠人声的音频或者视频素材拖入软件。
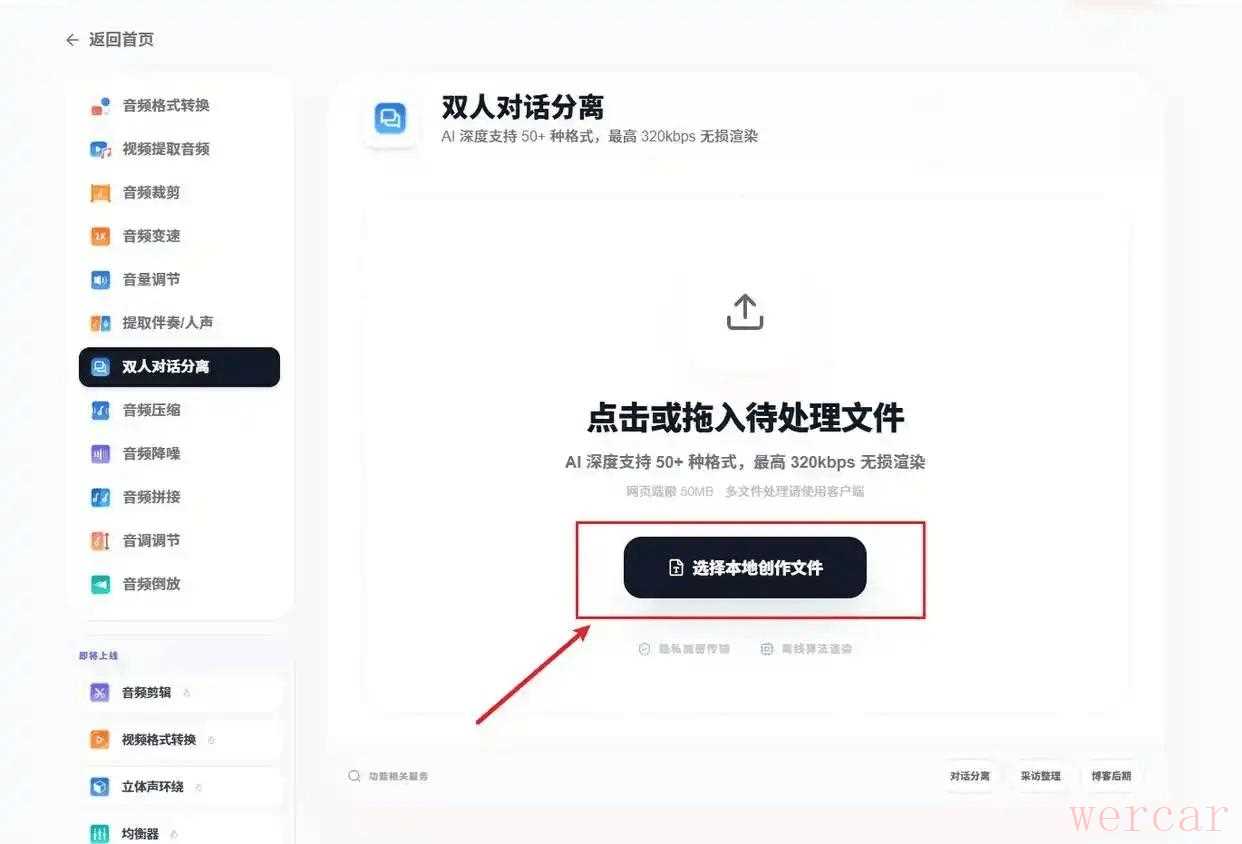
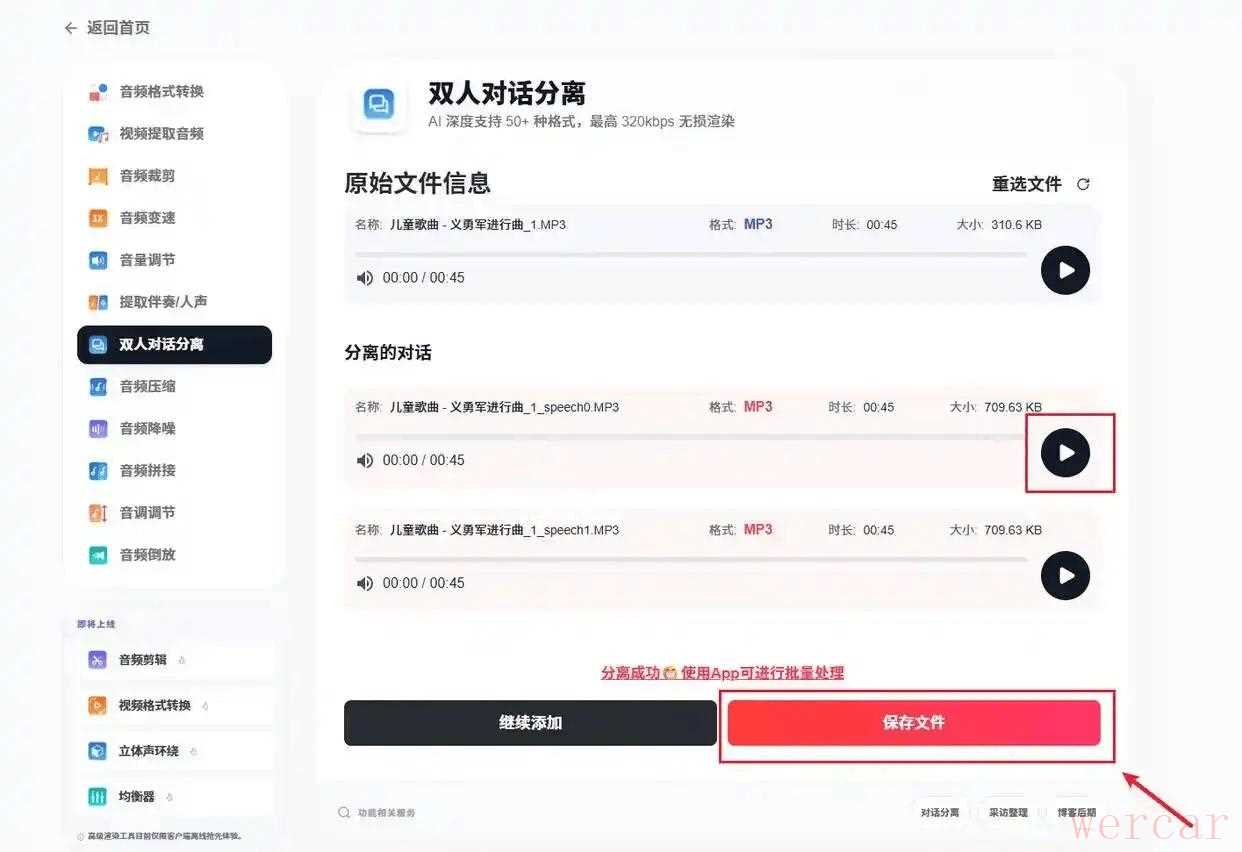
2、软件会自动识别音轨。针对重叠人声,默认选择“默认分离模型”,点击开始按钮,试听分离后的纯净人声效果。分离出的音频清晰度极高,底噪极小。
方法二:转换猫 MP3 转换器 App(安卓版)
想给手机里的短视频快速去噪,转换猫 App 绝对是安卓端的不二之选。它的 UI 设计非常符合数码博主的使用习惯,简洁且没有冗余广告。
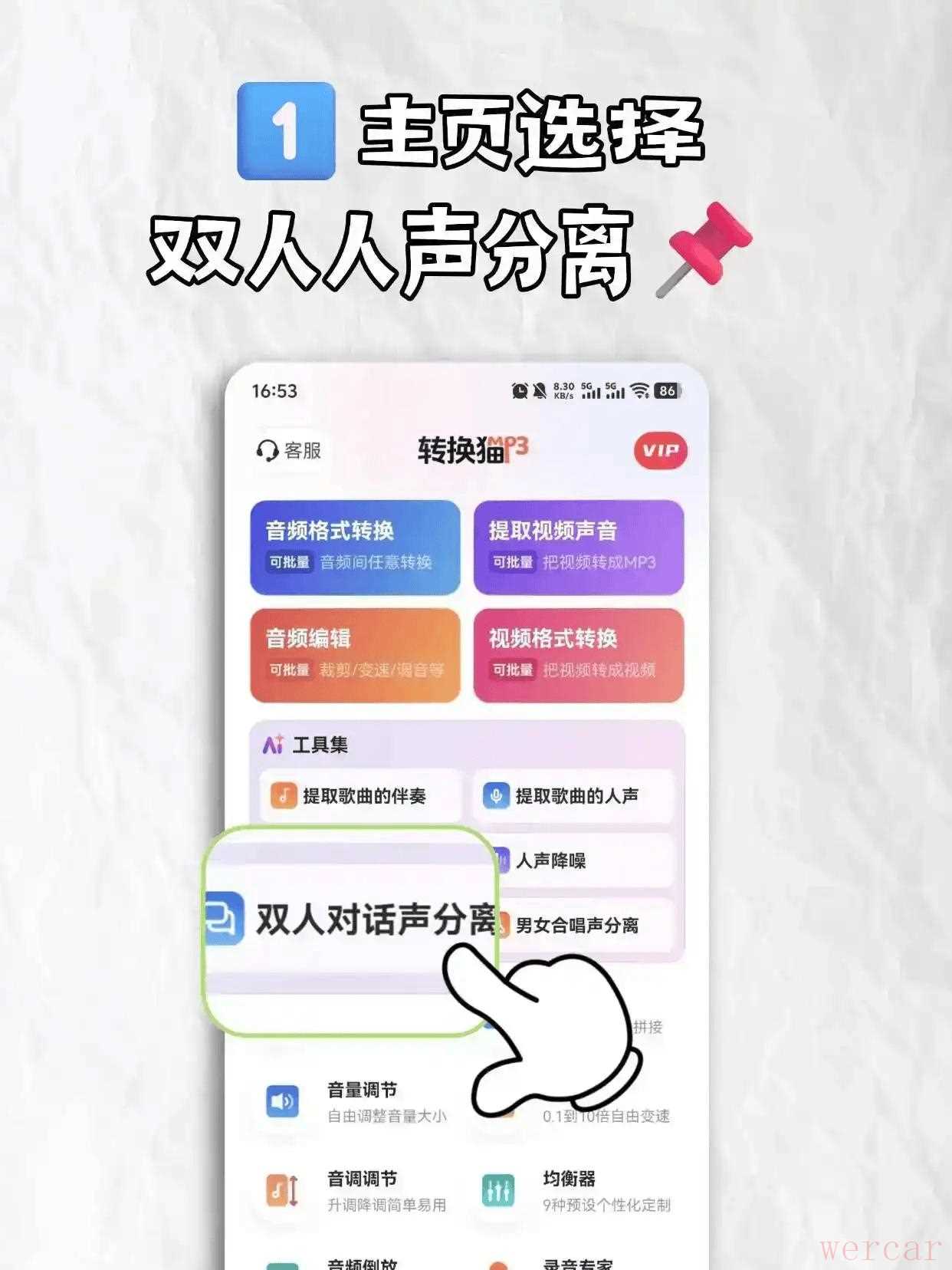
1、打开 App 首页,点击核心功能区的“双人对话分离”图标。从系统相册或文件管理器中选中包含重叠人声的视频或音频文件。
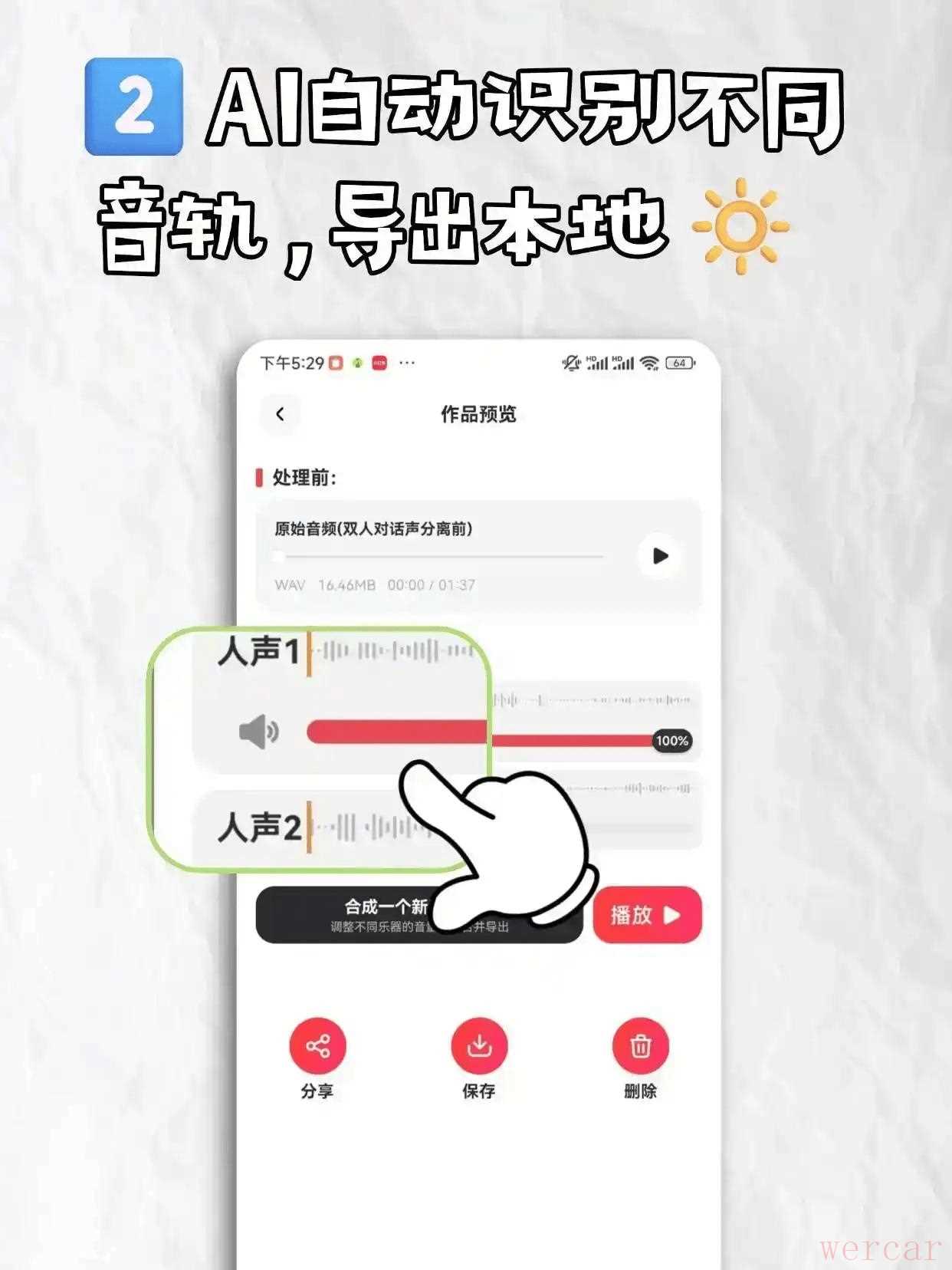
2、确认文件后,App 会将音频数据包传输至云端 AI 进行毫秒级的计算。处理完成后,界面会展示两条音轨:两条剥离出的纯净人声。播放实时比对,点击“保存”按钮存到手机内。
方法三:LALAL.AI
最大的特色在于可以进行多轨道细分,不仅能分出人声和伴奏,甚至能分出鼓声、贝斯、钢琴,这对于处理复杂重叠音频极具参考价值。
1、登录 LALAL.AI 网页。在上传框中,你可以选择“Stem separation type”(音轨分离类型)。针对我们的需求,选择“Voice and Noise(语音与噪音)”。
2、上传音频后,服务器会自动生成几个片段的预览。满意的话点击“Process the entire file”。由于是国外软件,处理速度取决于你的网络状况。
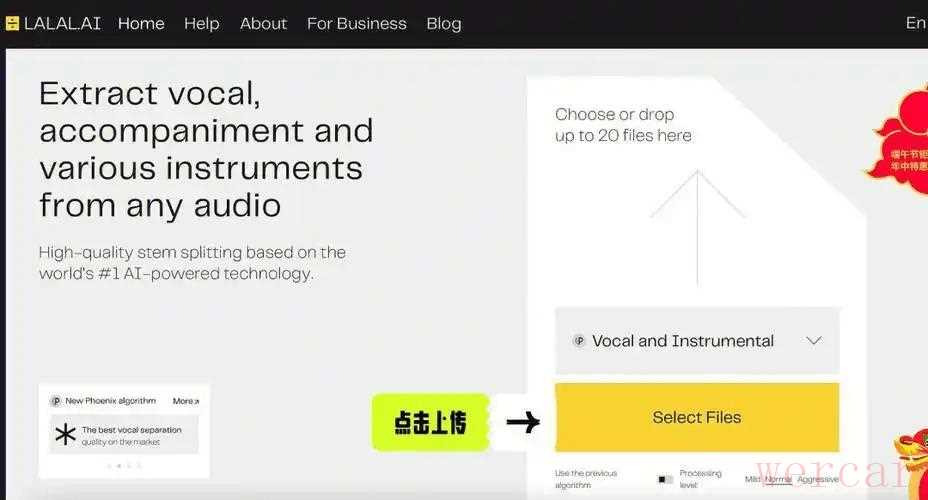
方法四:Ultimate Vocal Remover v5 (UVR5)
集成了全球多个顶级 AI 模型(如 MDX-Net、VR Architecture 等),是目前针对“人声重叠”分离效果最强悍的免费工具。
1、打开 UVR5,在“Process Method”中选择“MDX-Net”。在“Model”下拉菜单中选择专门针对人声的模型。勾选“GPU Conversion”以加速处理。
2、点击“Start Processing”。软件会将音频中的每一个频率点进行像素级的拆解,重叠的人声会被极大地削减干涉。软件全英文,设置好一次模板后,后续使用效率会变高。
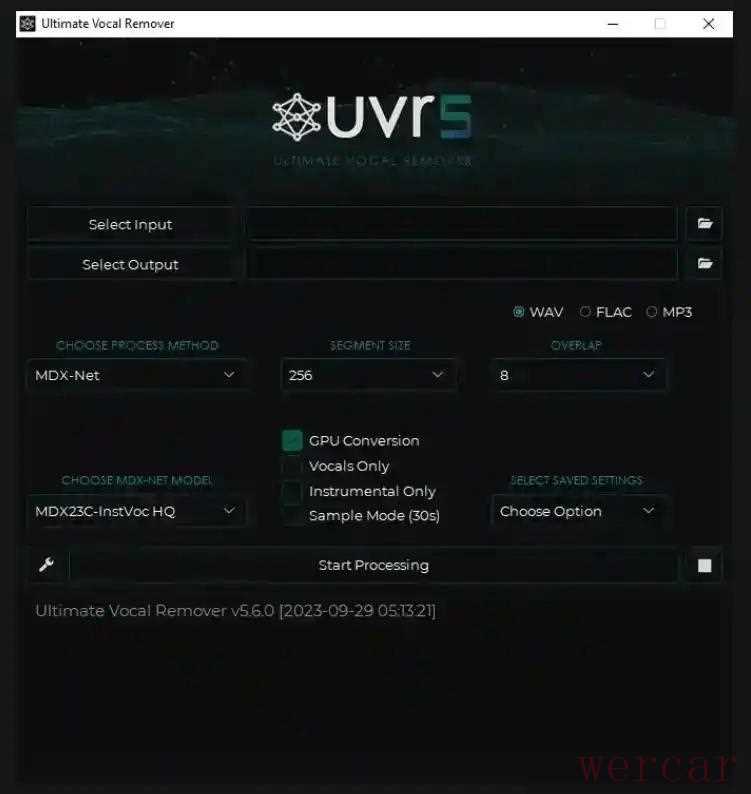
方法五:iZotope RX 10
电影工业界,iZotope RX 被称为“音频处理界的 Photoshop”。它的 Dialogue Isolate(对话隔离) 功能是专门为解决重叠背景音和多说话人干扰设计的,效果极为惊艳。
1、将音频导入 iZotope RX 10。右侧 Module 栏找到“Dialogue Isolate”。新版本支持 AI 神经网络,能自动识别什么是“有效对话”,什么是“环境干扰”。
2、调整“Sensitivity(灵敏度)”滑块,如果重叠声太强,就提高灵敏度。点击“Preview”试听,确定人声没有变得“闷哑”后,点击右下角的“Render”。
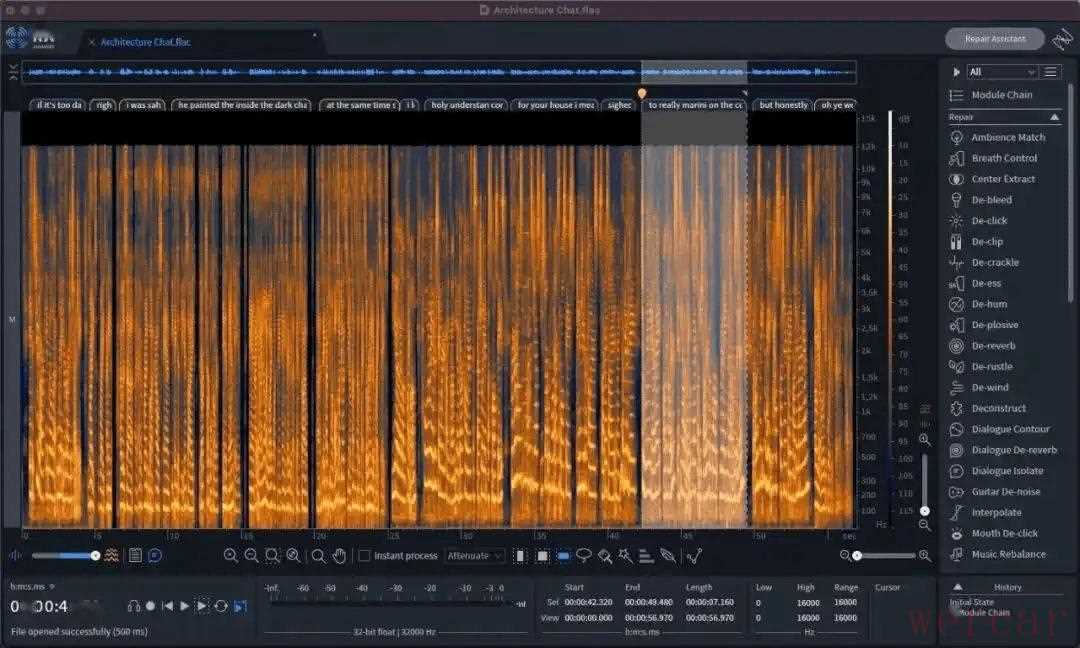
方法六:Adobe Audition
对于习惯 Adobe 全家桶的博主,Audition(AU)内置的中置声道提取器其实就是一个隐藏的“黑科技”,能够通过声相位置来分离重叠的对话。
1、进入 AU 编辑界面,点击“效果”菜单 -> “立体声声像” -> “中置声道提取器”。
2、弹出的窗口中,将“预设”改为“移除人声”或“提取人声”。针对重叠人声,选择“提取人声”。调整“中置声道电平”和“侧边声道电平”。
如何选择最适合你的工具?
小白新手/快速出片: 直接用 转换猫 Windows 版或 App,操作最简单,效果对得起效率。
极致画质党/专业发烧友: 选 UVR5 或 LALAL.AI,模型多,上限高。
企业级需求/电影质感: 毫不犹豫选 iZotope RX 10,除了贵(或难找),没别的毛病。
希望这篇教程能帮你解决音频剪辑中的“重叠人声”大麻烦。如果你在操作过程中遇到任何软件安装或参数设置的问题,欢迎在评论区给我留言!